데이터 분석 플랫폼인 Kaggle에 대한 소개와 데이터 분석 기초에 많이 사용되는 ‘Titanic: Machine Learning from Disaster’ 자료를 분석하는 과정에 대한 이야기 입니다. 분석에 사용한 코드들이 있지만 사실 코드보다는 kaggle의 사용, 그리고 주어진 데이터를 분석해 가는 과정에 중점에 둔 경험을 소개해 드리려고 합니다.
Kaggle?
Kaggle은 2010년 설립되고, 2017년 3월 Google에 인수된 데이터 분석 플랫폼입니다. 기업 또는 개인이 보유하고 있는 다양한 데이터가 이곳을 통해 공개되면, 이곳에 등록한 전세계의 데이터 분석가들이 이를 분석하고 결과를 비교하며 경쟁을 하는 곳입니다.
공개된 데이터들은 위 메뉴의 Competitions과 Datasets에서 확인할 수 있는데, Competitions의 경우에는 데이터와 함께 도출하고자 하는 결과에 대한 정보가 주어지고 이를 요구하는 포맷에 맞게 등록하면 결과에 따라 점수가 매겨집니다. 각 주제 별로 보상이 걸려있기 때문에 전문가들이 자발적으로 최선의 결과를 도출할 수 있도록 경쟁이 이루어 집니다. 다만 비공개나 참여가 제한된 주제들도 있습니다.

Datasets은 데이터만 주어질 뿐 주제나 결과의 우열에 관한 내용이 없기 때문에, 참여자들이 자유롭게 분석하고 이를 공유하는 데에 초점을 맞추었습니다. 이곳에서는 오히려 좋은 데이터를 공유한 사람에게 상금이 주어집니다;;;
데이터의 분석은 script또는 notebook의 포맷으로 진행할 수 있는데, 자기 컴퓨터에 설치한 IPython/Jupyter Notebook 에서 작업하는 것처럼 kaggle에서 제공하는 인터프리터(Python의 경우 Anaconda 3.6.3)로 직접 실행해볼 수 있습니다. 여기에서는 이를 묶어서 kernel로 관리합니다. 각 dataset 또는 competition별로 자기 kernel를 만들어서 데이터를 분석하고 결과를 공유하며, GitHub처럼 남의 kernel에 있는 notebook을 fork하는 것도 가능합니다.
좀 설명이 복잡해졌지만, 그냥 컴퓨터로 작성하고 실행할 수 있는 분석노트라고 생각하시면 됩니다.
여기에 있는 모든 kernel들은 Jupyter Notebook이나 script 형식으로 공개되기 때문에 데이터 분석을 공부하는 사람들에게 많은 도움이 되고 있습니다. 뿐만 아니라 분석가들의 랭킹(경쟁 별 순위나 데이터 분석 노트 평가 등을 기준으로 계산)도 공개되며, 상위권에는 AirBnB같은 유명 기업이나 H2O.ai 같은 인공지능 플랫폼 회사의 분석가들이 있어 그들이 진행한 분석 데이터를 보면서 노하우를 익힐 수도 있습니다.
(1위의 Gilberto는 AirBnB의 Data 분석가라고 하는데, 꽤 오랫동안 1위에서 안 내려온 듯…)

분석에는 일반적으로 데이터 분석에 가장 많이 쓰이는 Python과 R 뿐 아니라 SQL, 그리고 요새 떠오르는 Julia의 인터프리터도 지원하고 있기 때문에 사용자가 익숙한 쪽으로 사용할 수 있습니다.
여기에 공개된 데이터들은…
- 뉴욕의 택시운행 데이터
- 유럽축구 경기데이터
- AirBnB 숙박 데이터
- 미국 입국자 승객 데이터
- 월별 공기 오염도 데이터
- …
등 2,000개 이상의 데이터가 csv, sql 등의 파일 형식으로 제공되며. 수치 등으로 이루어진 단순한 데이터부터 장문의 텍스트, 이미지 등 복잡한 데이터까지 주제에 따라 다양한 포맷으로 되어있습니다.
Python의 경우, 수치나 단어들로 구성된 데이터라면 pandas, scikit-learn같은 가장 범용적인 데이터 분석 툴로 충분하겠지만, 긴 문장이 들어간 데이터라면 nltk같은 자연어 처리 툴이 필요하게 되고, 이미지까지 포함된다면 opencv등의 모듈을 사용해서 분석을 진행하게 될 것입니다. 물론 tensorflow, caffe같은 유명 딥러닝 툴도 사용할 수 있습니다.
언어든 도구든 각자 알아서…중요한 건 목적에 맞는 좋은 모델을 만들어서 예측의 정확도를 높이는 것입니다.
Titanic: Machine Learning from Disaster
Kaggle에 등록을 마치면, 입문자에게 tutorial로 권하는 competition이 바로 이 Titanic: Machine Learning from Disaster입니다. 여기서는 타이타닉 호 침몰 당시의 승객 명단 데이터가 제공되는데, 아래와 같이 생존자의 이름, 성별, 나이, 티켓요금, 생사여부 등의 정보가 포함되어 있습니다. 이 tutorial의 목적은 이 데이터를 통해 생존자의 생사여부와 다른 데이터들 간의 연관성을 분석하여 생존에 영향을 미치는 요소를 찾아내는 것입니다.
데이터가 비교적 분석에 용이한 형식을 갖춘데다가, 오래된 competition이다 보니 여러 사용자들이 강의노트 형식으로 올려놓은 공개 notebook도 많아서 데이터 분석 입문 및 적응에 여러모로 좋습니다. 물론 이 글의 작성에도 공개자료들의 많은 부분을 참고하였습니다.
다음은 분석을 위해 제공되는 데이터이며, csv 포맷으로 되어 있습니다.

시트의 각 column은 다음을 의미합니다. 이 항목들을 가지고 생존에 영향을 미친 요소를 도출해내는 과정을 진행할 것입니다.
- Survived: 생존 여부 => 0 = No, 1 = Yes
- pclass: 티켓 등급 => 1 = 1st, 2 = 2nd, 3 = 3rd
- Sex: 성별
- Age: 나이
- Sibsp: 함께 탑승한 형제자매, 배우자의 수
- Parch: 함께 탑승한 부모, 자식의 수
- Ticket: 티켓 번호
- Fare: 운임
- Cabin: 객실 번호
- Embarked: 탑승 항구 => C = Cherbourg, Q = Queenstown, S = Southampton
데이터는 train.csv(훈련 데이터), test.csv(목적 데이터) 두 가지가 제공되는데 목적 데이터의 경우에는 위 항목에서 ‘Survived’, 즉 생존여부에 대한 정보가 빠져 있습니다. 지금부터 훈련 데이터에 있는 정보를 통해서 적합한 분석 model을 구성한 뒤 이를 목적 데이터에 반영하여 생존여부를 추측하는 과정을 수행해 보려고 합니다.
아래의 New Kernel를 선택해서 분석을 시작할 수 있는데, 여기에서는 Python notebook을 사용하도록 하겠습니다.

초기설정 및 데이터 보기
|
|
처음 notebook을 생성하면 첫 cell에 위와 같은 코드가 준비되어 있습니다. 첫 두 줄은 numpy와 pandas를 호출하는 부분인데, 보통 저 두 라이브러리는 데이터 분석에서 기본적으로 사용하다 보니 준비한 것 같습니다.
특히 이 글에서 대부분의 프로세스는 pandas를 통해 이루어지기 때문에 혹시 잘 모르는 부분이라면 tutorial를 참고해 주세요.
(대부분의 다른 데이터 분석 모듈들이 pandas의 형식으로 데이터를 받아들이기 때문에 Python으로 데이터 분석을 배우겠다면 pandas와는 무조건 친해져야 합니다…좋든 싫든…)
밑에 두 줄은 주석에 있는 것처럼 위에서 설명한 입력 데이터, 여기에서는 train.csv, test.csv 파일을 호출하기 위한 경로를 알려주는 용도입니다. 여기에서는 이 데이터를 pandas에 탑재해서 사용할 것이기 때문에 아래와 같이 데이터를 import 합니다.
|
|
이제 kernel을 돌리면 pandas에 데이터가 적절하게 들어갔는지 확인할 수 있습니다.

데이터 읽기
흔히 데이터 분석의 첫 과정은 데이터와 친해지는 것이라고들 합니다. 데이터를 쭉 읽으면서 어떤 항목에 어떤 값이 있고, 어떤 흐름이 있는지 대략적으로 보는 과정인데, 당연하지만 숫자로만 보면 머리도 아프고 눈에 들어오지도 않습니다. 그렇기 때문에 보통 시각화, 즉 visualizing 과정을 수행합니다.
Python에서 주로 많이 사용하는 시각화 도구는 대표선수인 matplotlib과 이를 기반으로 확장된 도구 seaborn, bokeh 등인데, 여기서는 본인의 개취에 의해 seaborn 기반으로 진행하도록 하겠습니다.
주제가 아닌 만큼 seaborn에 대한 상세한 가이드는 생략하겠습니다.
먼저 시각화를 위한 패키지들을 추가하고, 가장 중요한 생사여부에 대한 정보를 시각적으로 표시하도록 하겠습니다. 훈련데이터가 들어간 데이터 프레임 train_df에서 Survived 키를 통해 생사여부의 정보를 가져올 수 있습니다.
|
|
위 코드를 kernel에서 실행하면 아래 차트를 확인할 수 있습니다.

위에 설명한 것처럼 0은 사망, 1은 생존을 의미합니다. 즉 탑승객의 60% 이상이 사망했다는 결론을 얻을 수 있습니다.
이번에는 남녀별 생존 비율을 확인해 보도록 하겠습니다. train_df['Survived']의 데이터에서 성별을 기준으로 필터링된 값을 가지고 비교를 해보면
|
|

그래프 색 때문에 약간 헷갈릴 수 있지만, 남자의 사망률은 80% 이상인 반면 여자의 사망률은 약 25%정도임을 확인할 수 있습니다. 즉 lady-first가 실천되었다고 예측할 수 있습니다.
이번에는 그래프가 아닌 pandas의 자체 table 기능을 사용해서 객실 등급 데이터인 Pclass를 검토해 보겠습니다.
|
|

이 테이블에서는 객실의 등급과 성별 별로 생존자 수를 확인할 수 있습니다. 여기에서 확인할 수 있는 정보들은…
- 1등 객실 여성의 생존률은 91/94 = 97%, 3등 객실 여성의 생존률은 50%
- 남성의 경우에 1등 객실 생존률은 37%, 3등 객실은 13%
즉 낮은 등급의 객실의 사망률이 높았다는 것으로, 좋은 자리값을 했다는 것을 볼 수 있습니다.
이번에는 ‘Embarked’, 즉 배를 탄 항구의 위치와의 연관성을 확인해 보도록 하겠습니다.
|
|

위 데이터를 보면 절반 이상의 승객이 ‘Southampton’에서 배를 탔으며, 여기에서 탑승한 승객의 70% 가량이 남성이었습니다. 현재까지 검토한 내용으로는 남성의 사망률이 여성보다 훨씬 높았기에 자연스럽게 ‘Southampton’에서 탑승한 승객의 사망률이 높게 나왔습니다.
또한 ‘Cherbourg’에서 탑승한 승객들은 1등 객실 승객의 비중 및 생존률이 높은 것으로 보아서 이 동네는 부자동네라는 것을 예상할 수 있습니다.
결과 도출을 위한 전처리(pre-processing)
이제는 위에 검토한 데이터인 ‘성별’, ‘객실 등급’, ‘탑승 항구’ 세 가지 정보를 가지고 생존률을 비교하는 로직을 만들어 보려고 합니다. 사실 이 이외에도 나이, 가족 구성원 수 등 많은 정보가 있지만 일단 이 3개 정보만을 사용하는 것은 전처리 과정(데이터 정제, 통합, 변환 등) 없이 현재 상태로 분석을 할 수 있는 포맷을 가지고 있기 때문입니다.
가장 단순하게 예를 들자면 ‘성별’과 ‘객실 등급’ 을 기준으로 분석한다고 할 때 데이터를 통해 여성 + 1등급 = 생존 이라는 공식이 도출되면 이후 여성 + 1등급이라는 정보가 나올 경우 이 로직에서는 이 승객을 생존으로 예측하게 될 것입니다. 하지만 기준을 ‘성별’과 ‘나이’로 생각할 경우 데이터를 통해 여성 + 33살 = 생존같은 형식의 로직이 나올텐데, 나이같은 연속적인 값이 기준이 되버리면 여성 + 32살, 여성 + 34살 같은 로직을 처리하지 못하는 등 판별기준이 매우 협소해지게 됩니다.
데이터 분석에서는 나이, 키, 가격 같은 연속적인 값들을 Continuous data, 성별, 등급 같은 특정 기준을 가지고 범위가 나누어지는 값들을 Categorical data로 표현하며, 보통 데이터 전처리 과정에서 ‘Continuous’ => ‘Categorical’ 변환 과정을 거치게 됩니다.
사실 이 데이터 전처리 과정이 데이터 분석 시간의 80% 정도를 차지한다고 할 정도로 중요한 부분이지만, 이 글의 취지에서 약간 벗어나게 되기도 하고 무엇보다 너무 이야기가 길어지는 관계로 이 부분은 다음번에 설명하도록 하겠습니다. 이미 너무 길어졌지만서도 ㅠㅠ;;
지금 이 세 가지 정보도 바로 사용할 수 없는게, 이 항목 중에 비어있는 데이터가 존재합니다.
|
|
|
|
지금 사용할 정보 중 ‘Embarked’(탑승 항구) 정보 중 2개가 빈 값으로 되어 있습니다. 이런 빈 값들은 데이터를 수집하는 과정에서 시스템 결함이나 사용자의 미입력 등에 의해 발생하는데, 일반적으로 ‘결측값’이라고 하는 이런 ‘빵꾸난’ 데이터를 처리하는 것도 전처리 과정의 일부입니다.전처리에 대한 부분은 이 글에서 다루지 않으려고 했지만, 이 부분을 처리하지 않으면 분석 진행이 안 되는 고로 일단 이 부분을 때우도록 하겠습니다.
실제 분석 시에는 이 빈 값을 채우는 과정에도 많은 예측과 경험을 필요로 하게 되지만, 여기서는 단순하게 이 두 사람은 사람이 제일 많이 탑승한 항구인 ‘Southampton’에서 탔다고 가정하겠습니다. 아무래도 많이 탑승한 항구라면 혼잡했을 테고 기록도 유실되었을 가능성이 많고 하니깐…
|
|
예측 model 생성 및 결과 제출
여기서는 이 데이터에 결정 트리 알고리즘 을 적용해서 데이터 모델링을 진행하려고 합니다. 모듈은 Python의 대표적인 데이터 분석 알고리즘 모듈인 scikit-learn에서 가져왔습니다.
이 글은 Kaggle competition에서의 결과 제출 및 확인을 위해 진행하는 것이기 때문에, 여기서도 역시 알고리즘과 모듈에 대한 설명은 최대한 생략하도록 하겠습니다. 알고리즘을 파고들기 시작하면 이 글이 끝나지 않을 것이니…그건 언젠가…
|
|
위 코드에 관해 간단히 설명드리면
- 분석 데이터를 train / test로 7:3 의 비율로 분리함
- X(기준), Y(결과)가 될 기준값을 설정함. X에는 ‘성별’, ‘객실 등급’, ‘탑승 항구’ 정보가 들어가며 Y에는 ‘생존여부’ 정보가 포함
- 결정트리 모듈에서 train 데이터를 학습시켜 로직을 도출함
- 로직의 결과값과 test 데이터를 비교하여 accuracy score(정확도)를 확인함.
여기에서 나온 accuracy score는 0.809701492537인데, 훈련 데이터의 모델링을 테스트 데이터에 적용했을 때 약 80% 정도의 정확도를 보여준다는 것입니다. 좋다 나쁘다에 대한 판별은 여러가지 요소를 고려해야 하는 부분이라 여기서는 확인만 하는 차원에서 넘어가도록 하겠습니다.
이제 이 model을 시작 전에 제공된 타겟 데이터와 매칭시킨 결과 얻은 뒤에 이를 출력하는 과정을 진행하겠습니다.
|
|
경쟁에 참여하기 위해서는 각 competition에서 요청하는 포맷의 파일을 출력해야 하며, 여기에서는 PassengerId(승객 ID)와 Survived(생존 여부)라는 두 개의 column으로 이루어진 csv 파일을 요구합니다. 위 코드에서는 test data에 있는 승객 ID와 test data에 modeling을 적용하여 얻은 ‘생존 여부’ 값을 가지고 csv를 구성하고 있습니다.
여기까지 완료된 뒤 우측 상단의 ‘Publish’ 누르면 현재까지 진행한 코드를 저장합니다.
제출 및 결과
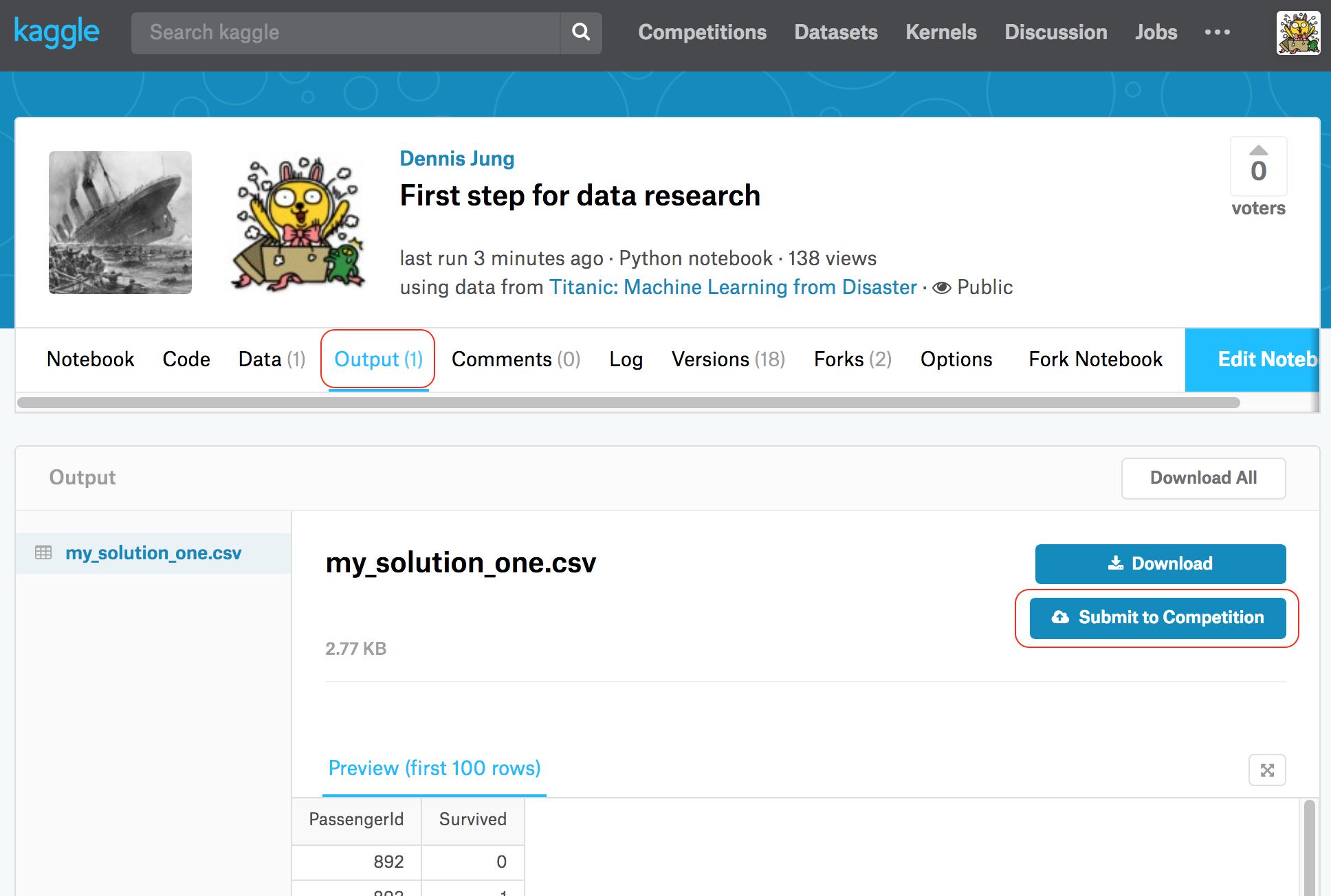
‘Publish’를 누르면 잠시 코드 처리가 진행되며, 제대로 완료가 되었다면 아래처럼 탭에 ‘Output’이라는 부분이 추가됩니다. 코드에서 출력한 csv를 표시하는 곳인데, 여기에서 ‘Submit to Competition’ 버튼을 누르면 해당 파일의 결과를 가지고 경쟁에 참여할 수 있습니다.
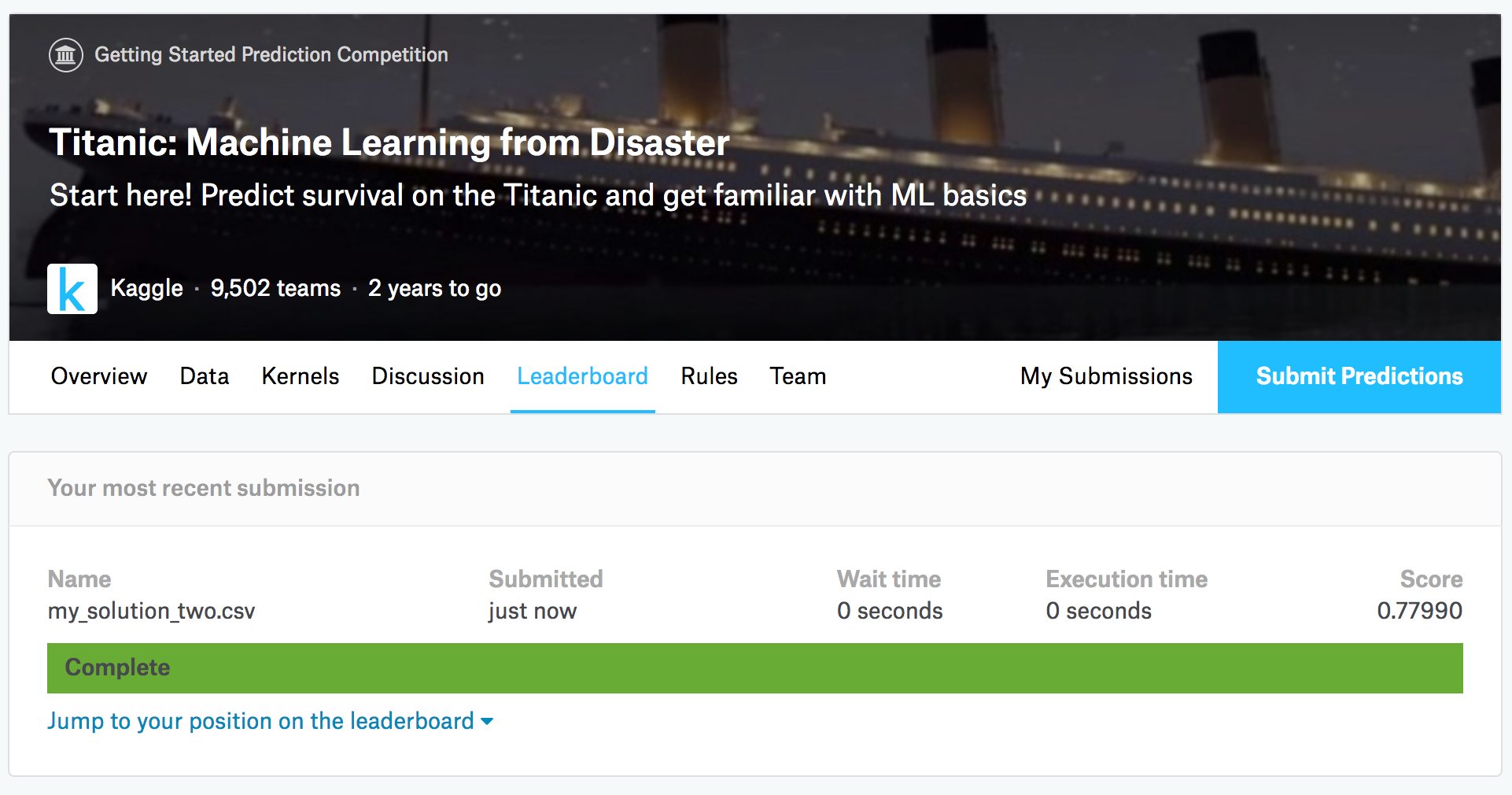
점수는 0~1 까지의 값이며, 수치가 높을 수록 예측치와 실제값이 맞는다는 의미입니다.
제 점수는요…0.77990으로 순위는 대략 9,500명 중 4,849등입니다. 물론 이번 결과는 알고리즘과 모듈의 힘을 빌린 거라 딱히 한 건 없지만;;;랭킹을 보다보면 score가 1인 사람들도 있는데, 예측치와 실제 정보가 전부 일치한다는 의미라 신뢰성에서 의심을 받고 있습니다. 점쟁이도 아니고…
토론장에서도 0.85 이상의 결과는 별 의미가 없으며 편법이 동원되었을 거라는 의견이 대부분입니다.
더 좋은 결과를 위해
좀 오래 전 그래프지만 score 별 분포도를 보면 0.7~0.8 사이에 대부분의 사용자들이 위치해 있으며, 지금도 참가자가 늘어났을지언정 이 비율은 크게 다르지 않습니다. 기본적인 프로세스 (결측값 처리 => 머신러닝 알고리즘 적용)을 사용한다면 어느 정도 수준의 model은 나온다는 것이지요.
이제 여기에서 0.0001을 높이기 위해 데이터 전처리 방식이나 최적화 알고리즘 검토 등 많은 분석 방법을 생각할 필요가 있습니다. 이 중에서 데이터 전처리에 대해서는 다음번에 간략하게나마 써보려고 합니다.
