저번 글에서 짧게 설명한 데이터 전처리에 대해 조금 더 깊게 들어가 보도록 하겠습니다.
데이터 전처리(Data pre-processing)
데이터 전처리라는 것은 이름 그대로 모델링 프로세스 전에 데이터를 모델링에 적합한 형태로 처리하는 절차를 의미합니다. 일반적으로 데이터 수집 프로세스는 규칙에 맞춰 통제되지 않는 경우가 많고, 그에 따라 예상되는 범위를 넘어가는 값들(자연수만을 가지고 있어야 하는 값에 -1이 들어가는 등)이나 존재할 수 없는 값들(나이가 5살인데 군필자)을 많이 포함하고 있습니다. 또한 데이터가 통제되더라도 분석 방향에 따라 적절한 변환을 거치지 않고 그대로 사용하는 경우 신뢰할 수 없는 결과를 도출하는 관계로 데이터를 처리하게 좋게 만드는 과정을 거치게 됩니다. 이 과정을 데이터 전처리라고 하며, 데이터 분석에 있어서 가장 많은 비중(노가다?)을 차지하는 부분입니다.
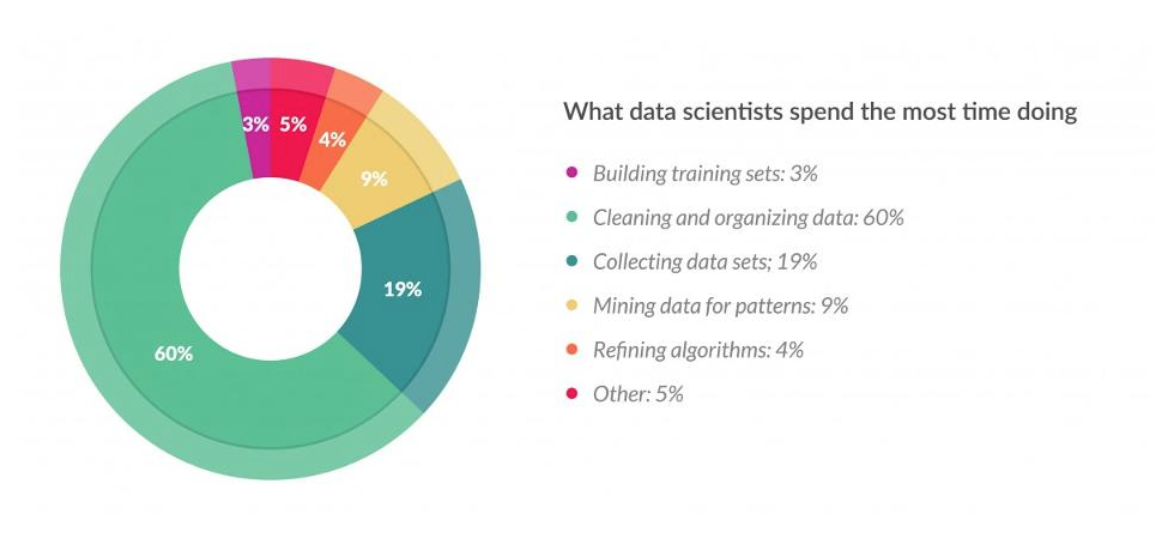
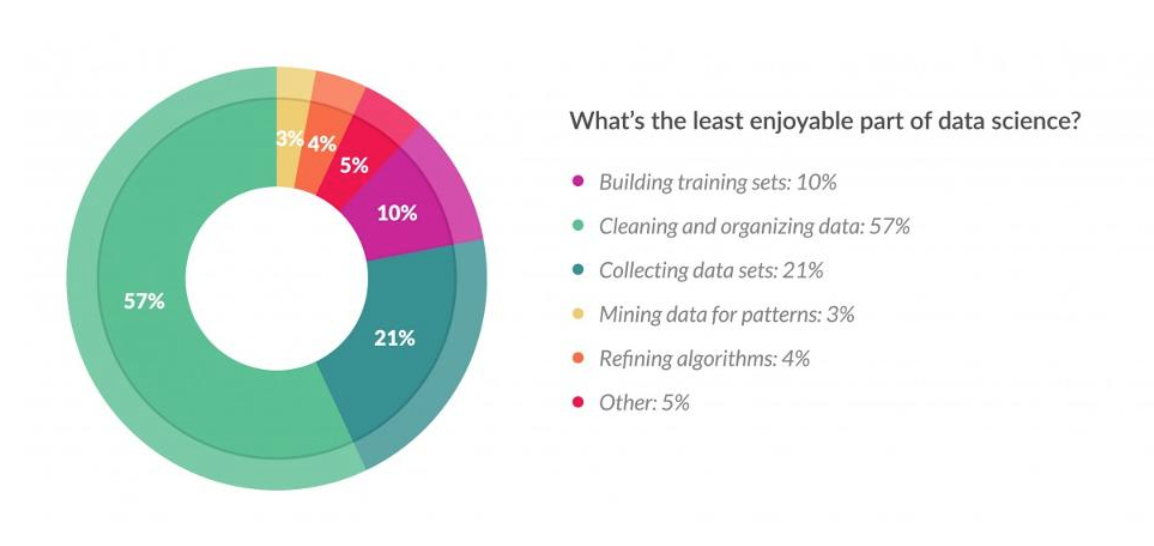
위에 나온 표는 데이터 과학자들을 대상으로 한 설문입니다. 표를 보면 데이터 분석 시간 중 60% 가량을 데이터의 전처리(데이터 청소 및 정제)에 보낸다고 나오며, 또한 절반 이상이 가장 지겨운(-_-) 과정으로 꼽았을 만큼 가장 오래 걸리고, 가장 번거로운 작업으로 볼 수 있습니다.
여기에선 저번에 진행했었던 Titanic: Machine Learning from Disaster의 분석에 이어서 몇 가지 전처리 과정을 진행한 뒤에, 이를 추가적으로 적용하여 이전 결과와 비교해 보는 과정을 진행해 보았습니다. 전처리에 대한 소개 및 전반적인 절차를 설명하는 것이 목적이기 때문에, 복잡한 수학식은 가급적 사용하지 않고 최대한 직관적으로 이해하기 쉬운 수준의 전처리만을 진행하도록 하겠습니다.
데이터 변환 및 속성 구축 - Name
Name 항목을 보면 특이할 만한 부분이, 성명 이외에 ‘Mr’, ‘Mrs’같은 일반적인 칭호 뿐 아니라 ‘Master’, ‘Dr’, ‘Sir’ 등 해당 승객의 직위나 신분 등을 추정해 낼 수 있는 정보들이 포함되어 있었습니다. 당시는 20세기 초였고, 영국은 신분별 차등이 남아있던 나라였기 때문에 이 정보 또한 생존과 연관성이 있을 가능성이 있었습니다. 때문에 우선 각 이름을 parsing한 새로운 column Title을 만들었습니다.
|
|
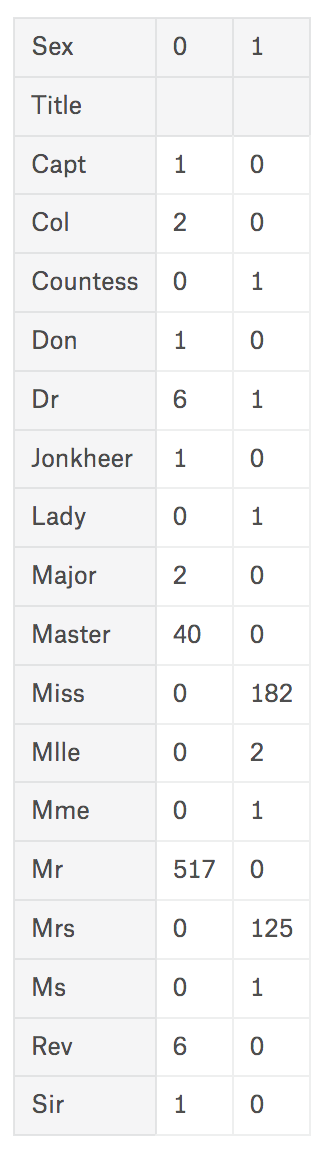
어느 정도 정리되었지만, 너무 종류가 많은 관계로 추가적인 범주화 과정을 진행하도록 하겠습니다. 위에서 언급한 대로, 이 속성을 만든 핵심 목적은 ‘신분’과 ‘생존’의 상관관계이기 때문에, 추정할 수 없는 사람들은 그대로 놓거나 별도의 값을 주도록 하고 비슷할 만한 신분을 가진 사람들끼리 Title을 통일시키도록 하겠습니다. ‘Mlle’는 ‘마드모아젤’, ‘Mme’는 ‘마담’의 약칭으로 사용되는 표기라서 각각 ‘Miss’, ‘Mrs’와 동일하게 취급하도록 했습니다.
- ‘Capt’, ‘Col’, ‘Don’, ‘Dr’, ‘Major’, ‘Rev’, ‘Jonkheer’, ‘Dona’ => Rare(기타 등등)
- ‘Countess’, ‘Lady’, ‘Sir’ => Royal(높으신 분들?)
- ‘Mlle’, ‘Ms’ => Miss
- ‘Mme’ => Mrs
위와 같이 Title을 재구성한 뒤에 이 정보와 생존률을 비교해 보겠습니다.
|
|
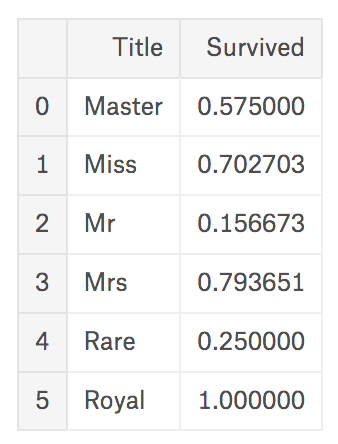
위 데이터는 재구성 뒤 각 Title별 생존률을 보여주고 있습니다. 여성인 ‘Miss’/‘Mrs’의 생존률은 이전 글에서도 보았듯이 높게 나타나고 있으며, 어느 정도 예상된 대로 ‘높으신 분들’로 추측할 수 있는 ‘Royal’/‘Master’의 Title을 가지고 있는 승객들의 생존자들 역시 다른 그룹에 비해 높게 나타나고 있습니다. 이 또한 생존률에 영향을 미치는 것으로 볼 수 있습니다.
결측값 처리 - Age
이전 글에서도 잠깐 설명했지만, 결측값은 쉽게 말해 빠진 데이터입니다. 결측값을 처리하지 않은 채로 진행할 경우 변수간의 관계가 정상적인 결과와 전혀 다르게 나올 수 있으며, 여기에선 아예 error가 나오는 관계로 미리 이 부분을 처리해둘 필요가 있습니다. 방법으로는…
- 삭제: 결측값이 발생한 데이터를 통째로 삭제
- 다른 값으로 대체: 평균값, 최빈값 등
- 예측값 삽입: 회귀분석 등의 방법 사용
이 있습니다. 여기에선 2번을 선택할 것인데,
같은
Title을 가진 사람들의 나이는 비슷할 것이다
라는 가정 하에 평균값을 나눠서 적용할 예정입니다.
|
|
|
|
위에 있는 데이터는 Title별 평균 나이입니다. 이제 Age정보가 빠져있는 인원들은 Title값에 따라 평균 나이를 채워넣도록 하겠습니다.
|
|
이제 Age정보를 사용할 수 있게 되었지만, 이전 글에서 잠깐 설명했듯이 연속적 형태를 가진 데이터는 지금의 목적과 같이 True/False를 판별하기 위한 정보로서는 부적합하기 때문에 추가적인 프로세싱을 진행하도록 할 것입니다.
통계적 데이터 binning - Age
데이터 binning은 bucketing이라고도 하며, 연속형 데이터를 특정 기준에 따라 더 작은 수의 그룹으로 나누는 것을 의미합니다. 영문으로 bin은 ‘저장용 통’을 의미하는데, 수많은 데이터를 몇 개의 통에 나눠서 넣는다는 의미에서 binning이라고 부르는 것 같습니다. 이제 AgeGroup이라는 항목을 새로 만들어서 나이를 binning한 결과를 저장하겠습니다. 기준은…
- Less than 7 : Baby & Kids (0)
- 8~20: Students (1)
- 21~30: Young Adults (2)
- 31~40: Adults (3)
- 41~60: Seniors (4)
- More than 60: Elders (5)
|
|
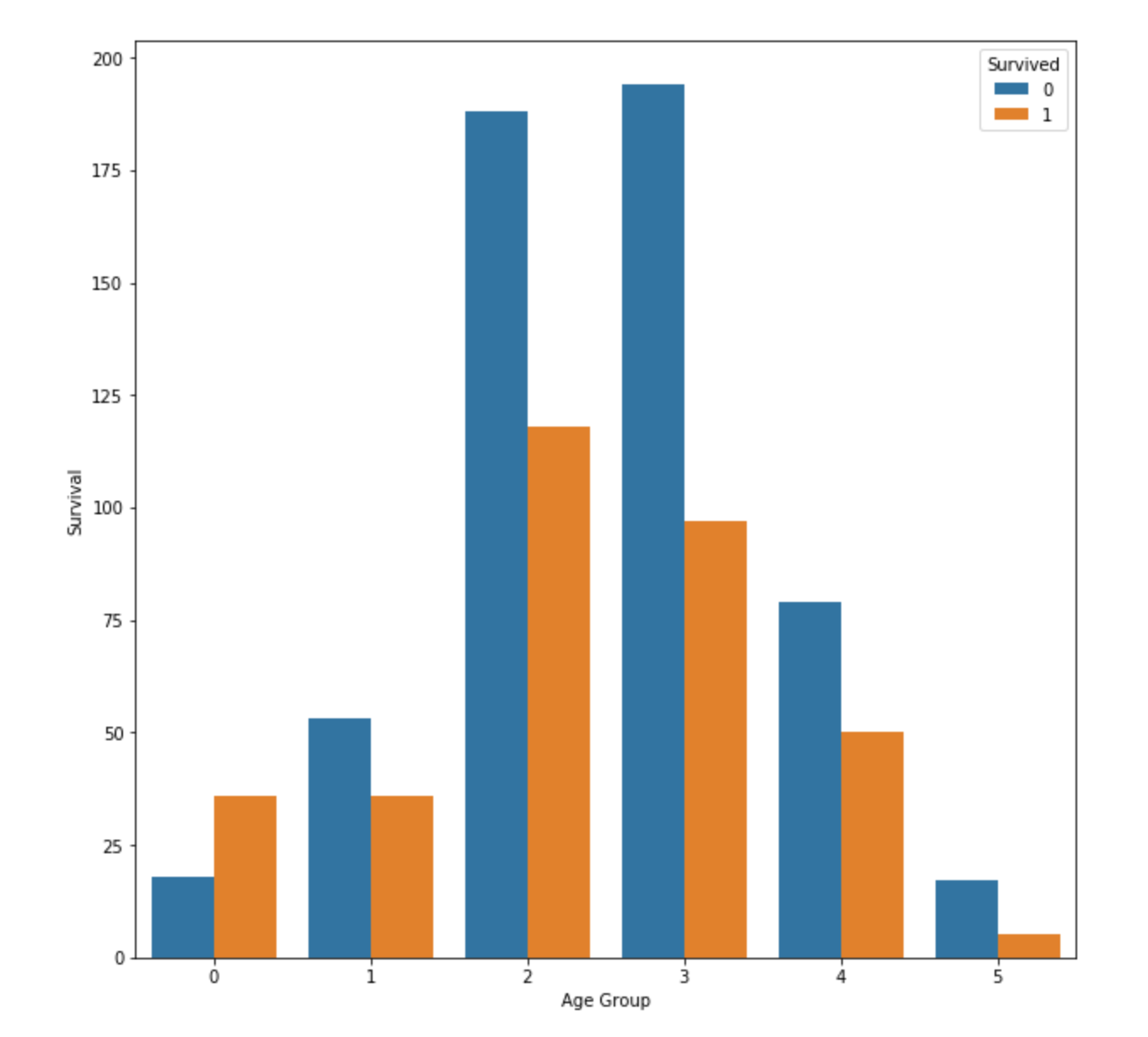
특기할 만한 것은 ‘Baby & Kids’의 생존률이 높게 나왔습니다. 그 이외에는 차이가 있지만 대체적으로 비슷합니다.
Binning과 반대로 dummy feature를 활용하여 범주형 데이터를 연속형 데이터로 변환하는 방법도 있지만, 이번 분석에서 필요한 과정은 아니니 생략하도록 하겠습니다.
이상값 처리와 데이터 binning - 동행 가족
이번에는 동행 가족에 대한 정보를 tuning하도록 하겠습니다. 현재 제공되는 data에는 SibSp(형제 + 배우자), Parch(부모 + 자식)으로 동행한 가족의 수에 대한 정보를 알 수 있는데, 제 상식 상 두 가지 속성의 우열을 가리기가 힘든 관계로(다들 소중합니다, 그쵸) FamilyMembers 하나로 통합하도록 하겠습니다.
|
|
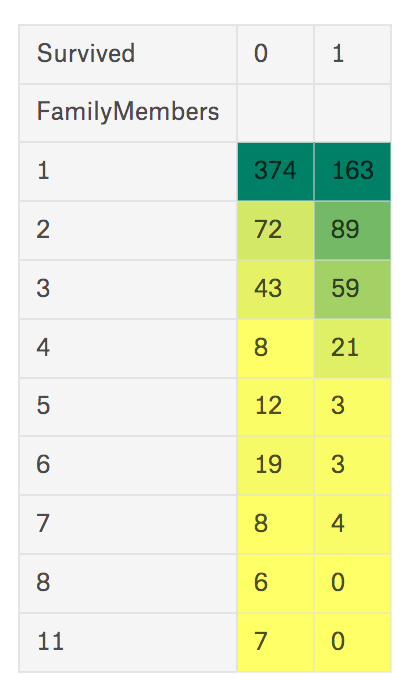
동행자가 없는 사람이 절반 이상이군요.
이상한 부분이, 구성원이 8명으로 기록된 사람이 6명이고 11명으로 기록된 사람이 7명입니다. 즉 데이터에 이상값(outlier)이 발생했다고 볼 수 있습니다. 이상값 또한 결측값 처럼 삭제 또는 다른 값으로 대체하는 방법이 있지만, 여기에선 예측 모델에 좀 더 맞도록 새로운 속성을 만들어보도록 하겠습니다. 이 속성은
‘동행자의 수’보다는 ‘동행자 유/무 여부’가 생존률의 추정에 더 적합할 것이다
라는 가정에서 출발합니다. 동행자가 있다면 생존하는 과정에서 협력할 가능성이 높기(물론 아닐 수도…) 때문입니다. 그래서 IsAlone이라는 속성을 새로 만들어서 가족이 있으면 0, 없으면 1로 정의하도록 했습니다.
|
|
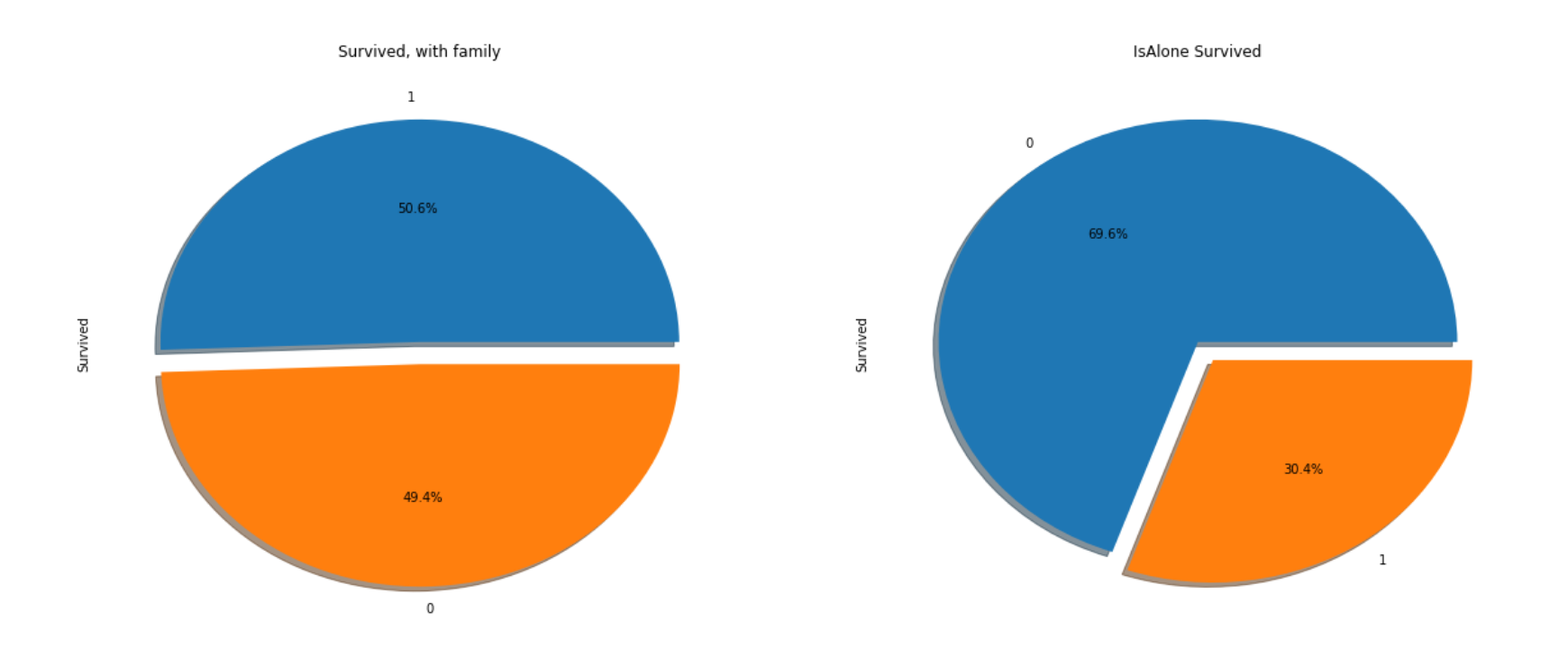
다행히(^^) 가정한 대로, 가족 구성원이 있는 경우가 생존률이 50%로 없는 경우(30%)에 비해 높은 것을 확인할 수 있었습니다.
이제 새롭게 구성된 속성을 추가해서 modeling을 진행해 보도록 하겠습니다.
예측 model 생성 ver.2
Modeling 방법은 이전과 동일하게 DecisionTree 알고리즘을 사용하였으며, 위 과정을 통해 추가된 속성 TitleKey, AgeGroup, IsAlone을 함께 적용하였습니다.
|
|
여기에서 나온 accuracy score는 0.813432835821로, 이전에 나왔던 0.809701492537보다 아~주 미세하게 높아진 것을 확인할 수 있습니다. 다만 이것은 어디까지나 내부적으로 분류한 train/test 데이터에 대한 결과로, 실제 대상 데이터의 결과는 이보다 더 낮아질 수도 있습니다.
데이터 분석에 있어서 테스트 데이터를 통한 예측 점수는 물론 중요하지만 그건 어디까지나 숫자상의 데이터와 알고리즘을 바탕으로 나온 것입니다. 데이터가 발생한 환경 및 시기에 대한 이해 없이 수학적으로만 계산된 데이터는 실제 환경에 적합하지 않을 가능성이 있으며, 그렇기 때문에 좋은 data model은 알고리즘 반영 이전에 데이터의 각 속성별 특징과 이를 통해서 얻고자 하는 목적과의 연관성, 사용할 알고리즘에 대한 폭넓은 지식을 바탕으로 한 데이터의 전처리 과정을 필요로 합니다.
